AI在新產品開發過程中的應用與展望
發布時間:2025-04-23 作者:PTC公司 段立淵 施戰備
1.引言
隨著AI技術和數字化技術的發展,人工智能正以前所未有的深度重構新產品開發流程中的每一個環節。從客戶畫像繪制到需求洞察,從系統工程設計到仿真測試,從原型開發到量產持續交付,從生產計劃預測到供應鏈風險評估,AI技術不僅壓縮了產品開發周期,更通過數據驅動的模式輔助企業決策,讓產品創新過程實現從"經驗驅動"、"既有知識驅動"到"數據驅動"的蛻變。
華為一直倡導的IPD成熟度模型,將企業的集成產品開發過程定義為五個階段,分別是工具集成、項目管理、需求驅動、產品組合、知識管理。而AI技術在知識管理的高度上實現了數據驅動的動態知識更新,基于歷史數據和不斷產生的實時數據,形成自學習優化的動態知識庫,在傳統數字化管理的百尺竿頭實現了更進一步的目標。
2.挑戰
隨著DeepSeek的橫空出世,眾多企業認為LLM技術在制造型企業的深度應用指日可待。然而企業在實戰驗證環節中,往往發現DeepSeek在回答專業問題時出現大量"幻覺",看似井井有條的推理分析實際上毫無用處。這是因為DeepSeek的知識庫主要為公開領域的顯性知識,而非垂直專業領域的隱性知識,更不用說企業本身還有大量基于自身市場定位、商業目標、設計規則、競爭姿態的獨特信息。
我們在近期走訪了大量企業,其中不乏電子高科技、新能源、醫療器械行業的頭部企業,大家在LLM的實踐中主要將DeepSeek這類模型用于通用法規和設計標準的一般問答,而在產品開發過程中卻鮮有應用。這是因為產品研發和流程中的數據存在多源異構的特點,并且區別于傳統的工業設備數據高體量低單位價值的狀況,研發流程數據具有中等體量高單位價值的特點。以設備產生的振動數據為例,現有技術能夠以毫秒級采集海量數據,通過云邊協作技術實現大數據分析,以預測設備故障和評價健康狀況。在工業設備數據分析的場景中如果丟失或錯誤存儲了部分數據,并不會對模型預測的結果有嚴重的負面影響,這是因為工業設備數據單位價值并不高,依賴規則化的數據清洗邏輯即可處理海量數據中的缺陷。遺憾的是產品開發過程的數據往往難以重走工業設備數據處理的老路,產品開發過程數據具有高單位價值的特點,一旦出現微觀級別的錯誤就可能導致嚴重的后果,更不用說通過這樣的數據開展大規模的預測活動。例如產品配方BOM中的配比屬性出現錯誤或空置,LLM技術并不能像處理工業設備數據一樣通過簡單的中值、眾數進行差值填補。一旦LLM模型學習錯誤或存在缺陷的知識(例如錯誤或過時的配方),將會給后續的原型開發和量產帶來災難性的后果。
3.破局
企業要想獲得足以應用于新產品開發能力提升的大模型,必須建立以"算力-算法-數據"三大支柱支撐的大模型底座。算力提供可行性,算法提供方法論,數據提供學習基礎。對于企業來說,算力和算法的挑戰并不是最大的難題。硬件資源(GPU/TPU集群)、分布式計算能力、云計算等模式趨于成熟,企業級解決方案的算力越來越強,已經能夠解決模型訓練的規模和速度問題。算法層面例如深度學習、強化學習應用在制造業的設備故障預測、產能預測和生產排程等領域應用的例子比比皆是。企業真正要重點優化的方向仍是數據質量的問題,大部分企業在嘗試DeepSeek等大模型訓練的時候,拿不出一套完整和正確的數據包。所以企業要想在大模型的開發與應用方向實現破局,必須夯實數字化基礎,完成多應用系統分頭并進的現狀到數字化轉型后數字主線拉通端到端應用的轉變。如果說算力和算法奠定了大模型應用的基石,那么數據質量就決定了AI應用的上限。
數據的治理和優化是一項長期和復雜的系統工程,企業必須建立面向角色的端到端應用,建立通用模型基礎上的垂域模型。而面向垂域模型的應用需要拉通企業級多應用系統。傳統的ERP/PLM/MES等系統作為企業應用的獨立界面,往往存在跨系統數據難以打通,各系統孤島獨立運行,數據分析要素分散缺失等問題。LLM建模的數據基礎需要通過數字主線技術拉通一系列系統中的業務流與數據流。如圖1所示,企業中的ERP/PLM/MES系統存在大量結構化、非結構化數據,LLM模型的知識來源就隱藏在此類離散的海量數據中。
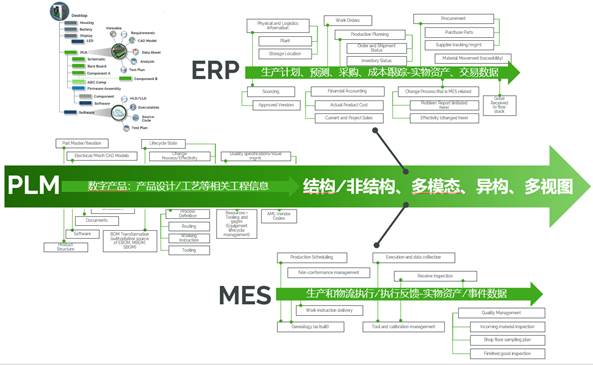
圖1
企業在開展系統間數字主線建設的同時,應該秉承以終為始的思路,考慮如何建立合理的主數據體系,并在海量數據中進行清洗、特征工程、建模、迭代優化等工作,將系統中產生的歷史數據和新產生的實時數據通過數據服務的形式持續性地組織分析,建立基于系統數據的模型自學習、自升級機制。
只要實現了LLM通用模型基礎上的垂域知識訓練與建模,在產品開發過程的每個階段都可以挖掘AI應用,例如通過爬蟲技術進行市場洞察、利用LLM模型虛擬大量用戶支撐需求優先級排序、利用生成式AI進行產品概念設計或增材制造設計、采用機器學習對測試活動進行缺陷預測、通過三點估測法結合深度學習預測項目成本或采購風險。基于上述能力就可構建應用級智能體,例如采購BOM預測Agent、基于需求的快速報價Agent、變更影響分析Agent……只有實現了底層系統數據打通和面向垂直領域應用的持續分析,才能實現產品開發過程數據的可自主讀取識別,逐漸達到數據可自主創造和自主決策的高度。如圖2所示,將PLM等系統數據進行結構化、圖譜化梳理,并建立持續的訓練與模型調優機制,對垂直領域大模型開展漸進優化,是建立企業級AI應用的必由之路。
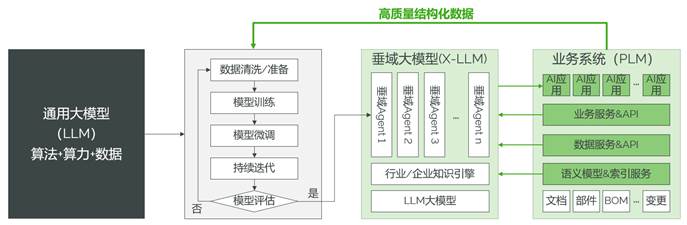
圖2
4.AI驅動的集成供應鏈優化
以集成供應鏈優化為例,AI技術能夠協助企業預測采購需求,推薦物料選型,求解最佳采購計劃,規避供應商交付風險,如圖3所示,AI技術在供應鏈優化方面能夠提供重要助力。
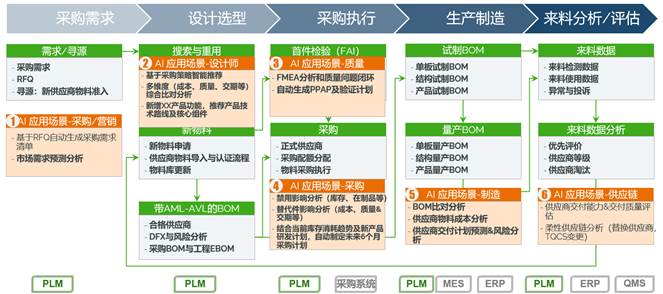
圖3
由于市場需求和供應鏈趨勢的波動,企業希望提前預測未來一段時間的采購計劃。企業可以通過建立市場趨勢、客戶需求、歷史銷售數據和采購數據的數字主線,結合時間序列模型和深度學習模型,預測未來的采購方案,以降低庫存壓力或物料短期風險。某車企通過時間序列ARIMA模型和深度學習LSTM模型預測6個月內的采購需求,實現訂單驅動的拉式生產零庫存管理,將庫存對資金占用的浪費降到最低。
AI技術也能夠幫助企業建立物料智能優選引擎,構筑物料采購規模效應。通過建立包含供應商歷史交貨準時率、質量合格率、價格波動、DOE結果、客訴數據的數字主線,構建面向物料的多維尺度評價模型,整合基于固有屬性的機理模型和基于歷史采用情況的數據模型,自動推薦最優供應商和物料,實現數據驅動的物料智能推薦。國內電子高科技行業某頭部企業已經開始使用上述方法針對電氣元器件進行AI智能優選的探索,并且取得了一定的成效。
Gartner預測到2028年,至少15%的日常工作決策將通過代理型AI自主做出。借助AI的力量,未來的集成供應鏈管理必將從傳統的"成本單元"轉型為構筑企業競爭力的"戰略單元"。
5.展望
人工智能技術是企業數字化轉型的重要驅動力,企業要想構建基于AI的數字化轉型能力就必須構建"算力-算法-數據"三位一體的底層架構。對于企業來說該架構的最大困難仍然在于高質量數據的突破,能否將嵌在多源異構系統和流程中的寶貴數據提煉并應用,是企業未來實現AI驅動數字化轉型的最大挑戰。如圖4所示,AI技術是未來驅動數字化轉型的核心驅動力,要想駕馭AI能力并實現落地應用,企業還有很長的路要走。
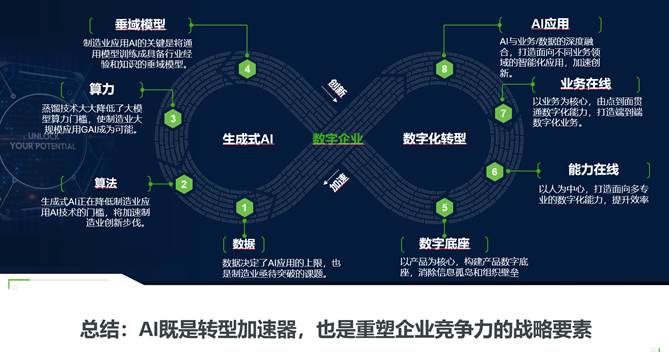
圖4
企業在這場沒有終點的AI競賽中想要勝出,除了需要構建"算力-算法-數據"三位一體的底層架構以外,還需要建立基于LLM通用模型基礎上的垂直領域模型,達到面向人員的能力在線和面向流程的業務在線,使其具備制造業專有的產品開發知識,用于促進多角色協同的產品開發工作。未來的產品競爭力,將取決于企業駕馭AI創新的能力。唯有將AI深度融入研發基因,方能在智能時代占據先機。